Une réappropriation des données par leur structuration
Et si nous envisagions la réappropriation des données par la question de leur structuration ? Un document, un article ou un livre peut être appréhendé, modifié, maîtrisé et manipulé si sa structuration est visible et compréhensible. À partir de trois exemples voici un billet qui prolonge ma participation à une table ronde lors des journées d’étude du DDAME à Toulouse les jeudi 15 et vendredi 16 mars 2018.
Les journées d’étude du DDAME
Les journées d’étude 2018 du Département documentation, archives, médiathèque et édition (DDAME) de l’Université Toulouse Jean Jaurès avaient pour sujet “La diffusion du patrimoine et de la culture à l’heure du web des connaissances. Structuration, partage et interconnexion des données”. La table ronde à laquelle j’ai participé aux côtés de Florence Clavaud (qui travaille aux Archives nationales) et de Nicholas Crofts (qui est consultant en informatique) s’intitulait “Universalité des modèles conceptuels de données, mutualisation des pratiques et prise en compte des usagers”. Je n’étais pas tout à fait dans le sujet, et je n’ai pas pu évoquer tout ce que j’avais prévu (c’est le jeu des tables rondes), voici donc trois idées développées.
À noter également que cette participation et ce billet accompagnent des recherches en cours sur les chaînes de publication : depuis ce billet jusqu’à un mémoire en cours de rédaction, ainsi que des articles et des communications, seuls ou aux côtés de Julie Blanc et de Thomas Parisot notamment.
Visibilité des documents patrimoniaux sur le Web
Le premier exemple de réutilisation de données est celui d’utilisateurs de documents patrimoniaux. Que ce soit pour sauvegarder des métadonnées ou partager une page de présentation d’un document, les usages peuvent être nombreux. Un des exemples désormais classiques est celui du partage d’une page web présentant un document patrimonial, sur les réseaux sociaux. Il y a encore quelques années ce partage se limitait à un simple lien, puis Facebook et Twitter ont mis en place des standards bien plus riches pour extraire et afficher les métadonnées d’une page web.
Facebook a créé le protocole Open Graph inspiré notamment par le Dublin Core. Twitter a créé le concept de Cards basé sur un fonctionnement similaire.
Prenons l’exemple de Twitter et de Gallica : lorsque vous partagez sur Twitter une page de présentation d’un document, comme cette photo des Archives nationales, Twitter va extraire automatiquement des informations indiquées dans les métadonnées de la page. Gallica utilise les données de la notice du document pour :
- afficher les informations sur la page web de présentation du document ;
- renseigner les métadonnées de cette page web pour le partage sur des réseaux sociaux comme Twitter ou Facebook.
Voici un schéma pour résumer ce fonctionnement assez simple :

Le code source de la page web présentant cette photo des Archives nationales comporte donc un certain nombre de métadonnées, voici un aperçu en image :
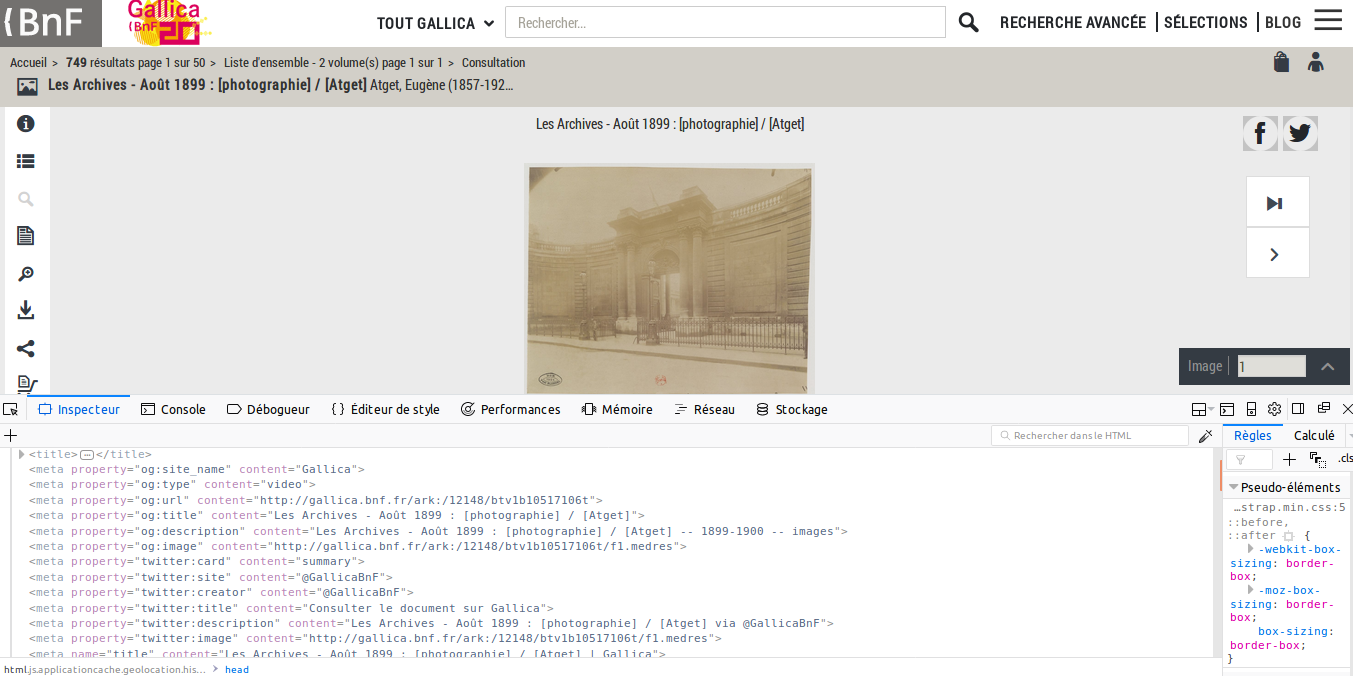
Le partage sur Twitter (ou sur Facebook) n’est pas le seul cas d’usage, il est aussi possible d’utiliser ces métadonnées pour enregistrer les références d’un document dans un système de gestion de références bibliographiques. Ainsi cette (simple) page web peut être un moyen d’enregistrer plusieurs informations sur ce document dans Zotero. Voici le schéma du dessus modifié en conséquence :

Les données d’un document, aussi riche soient-elles, peuvent donc être facilement partagées avec des outils accessibles comme les réseaux sociaux, ou des outils plus professionnels comme des outils de gestion de références, à condition d’adapter l’affichage visible et en partie invisible de ces données – ici une page web.
Structuration des données : l’exemple de l’édition de livres
Déplaçons-nous dans le domaine de l’édition. J’utilise un exemple que je connais désormais bien, il s’agit de la chaîne de publication Quire développée par le département numérique de Getty Publications. Nous pouvons noter que d’autres exemples existent, notamment The Electric Book workflow développé par Fire and Lion.
Des chaînes de publication monolithiques
La situation des chaînes de publication dans l’édition est la suivante :
- édition généraliste : utilisation des deux outils Word (traitement de texte) et InDesign (logiciel de publication assistée par ordinateur) ;
- édition universitaire : chaînes de publication puissantes mais complexes (avec intégration d’XML TEI notamment).
Plusieurs constats peuvent être faits : une confusion entre structure et mise en forme, des étapes d’édition définitives (le retour en arrière est soit impossible, soit très compliqué), une dépendance à des outils fermés et monolithiques, une pérennité limitée, une difficulté de compréhension de la structuration des données, des formats illisibles sans les interfaces complexes qui vont avec, etc.
Nous pourrions résumer (très grossièrement, j’en conviens) la situation actuelle avec le schéma suivant – il faut noter ici le sens unilatérale des flèches :

Des chaînes de publication modulaires
Ce que Getty Publications a voulu mettre en place avec Quire, c’est répondre à un certain nombre de critères, dont les suivants :
- distinguer structure et mise en forme pour les rédacteurs/auteurs, avec un langage lisible par les humains ;
- conserver le même format/fichier dans toutes les étapes ;
- prévoir la réversibilité des étapes ;
- générer différents formats : PDFs, EPUB, web, jeux de données, etc.
Le résultat schématisé donnerait ceci :

Nous pouvons prendre l’exemple du livre Ancient Terracottas publié par Getty Publications :
- le livre est disponible sous différents formats ou versions – visibles depuis le menu du site dans la partie “Downloads” : site web, EPUB, PDF, version imprimée ;
- certaines données peuvent également être exportée au format de tableur CSV – visibles depuis le menu du site dans la partie “Object Data” ;
- les contenus de ce catalogue sont gérés dans des fichiers au format YML – un format de description de données très simples – ou au format Markdown dans le cas d’autres livres de Getty Publications ;
- les sources sont gérées avec Git et la plateforme GitHub.
Là où une chaîne classique impose une certaine perméabilité des étapes d’édition, cette chaîne de publication modulaire permet aux différents intervenants d’être tous au même niveau. Un correcteur peut encore intervenir sur le texte après la mise en forme, un graphiste peut déjà préparer la maquette et la mise en forme avant la fin de l’écriture ou de la correction. Chacun peut se réapproprier le livre pendant sa conception et sa fabrication.
Permettre l’interaction sur un texte
Le troisième exemple est celui de Distill, une revue numérique sur le machine learning. L’originalité de cette revue de recherche universitaire est double :
- elle intègre des diagrammes interactifs – ou reactive diagrams – qui permettent une meilleure compréhension des concepts présentés ;
- les contenus des articles sont gérés comme du code, c’est-à-dire qu’ils sont versionnés.
Pour versionner les fichiers qui constituent les articles, Distill utilise la plateforme GitHub – GitHub est un service d’hébergement et de gestion de développement de code, utilisant le système de contrôle de versions Git. Chaque article a un dépôt dédié, chaque modification ou série de modifications est donc visible, comme on peut le voir dans le schéma ci-dessous.

Voici un exemple d’historique de version pour un article sur GitHub :
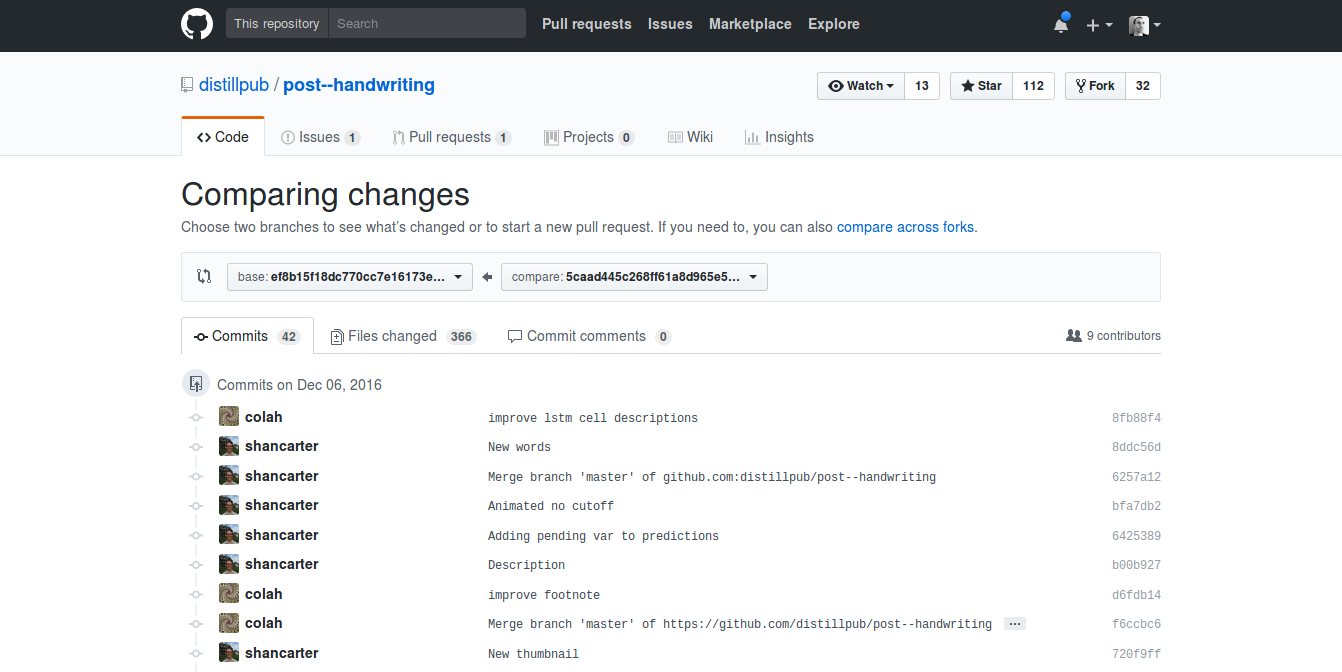
Cette gestion des contenus comme du code est possible justement parce que les données des articles sont structurées avec un langage de balisage, ici le format utilisé est HTML avec un schéma spécifique – précis mais relativement simple à manipuler –, Distill propose un guide pour comprendre son fonctionnement.
Dans cet exemple tous les contributeurs peuvent être au même niveau : il n’y a pas de changement d’outil pendant les différentes phases de gestion des articles, les modifications sont visibles par toutes et tous, chaque personne peut s’approprier les contenus avec la contrainte de la compréhension d’un langage de balisage comme HTML et d’un système de gestion de versions comme Git – ce qui est tout de même un effort et un temps d’apprentissage non négligeable, mais cette possibilité existe.